Binarly
The most important feature of the upcoming yarGen YARA Rule Generator release is the Binarly API integration.
Binarly is a “binary search engine” that can search arbitrary byte patterns through the contents of tens of millions of samples, instantly. It allows you to quickly get answers to questions like:
- “What other files contain this code/string?”
- “Can this code/string be found in clean applications or malware samples?”
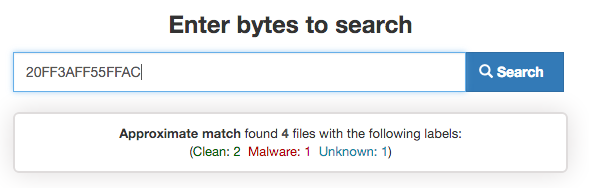
Binary Search Engine – Binar.ly
This means that you can use Binarly to quickly verify the quality of your YARA strings.
Furthermore, Binarly has a YARA file search functionality, which you can use to scan their entire collection (currently at 7.5+ Million PE files, 3.5M clean – over 6TB) with your rule in a less than a minute.
For yarGen I integrated their API from https://github.com/binarlyhq/binarly-sdk.
In order to be able to use it you just need an API key that you can get for free if you contact them at contact@binar.ly. They are looking for researchers interested in testing the service. They limit the requests per day to 10,000 for free accounts – which is plenty. yarGen uses between 50 and 500 requests per sample during rule generation.
The following screenshot shows Binarly lookups in yarGen’s debugging mode. You can see that some of the strings produce a pretty high score. This score is added to the total score, which decides if a string gets included in the final YARA rule. The score generation process from the Binarly results is more complex than it might seem. For example, I had to score samples down that had 3000+ malware but also 1000 goodware matches. The goodware matches have higher weight than the malware matches. A string could have 15.000+ malware matches – if it also appears in 1000 goodware matches it does not serve as a good YARA rule string. I also handled cases in which small result sets lead to high Binarly scores.
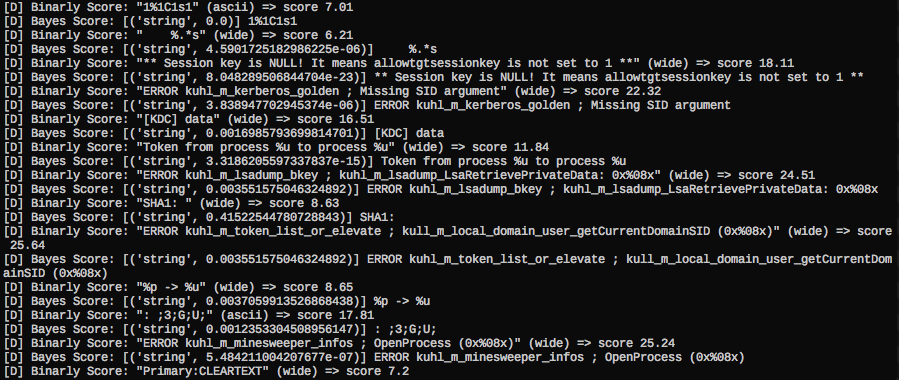
Binarly Service Lookup in yarGen 0.16
Therefore the evaluation method that generates the score of each string has been further improved in the new version 0.16.0 of yarGen. Both the Binarly service and the new yarGen version are still ‘testing’. Do not upgrade your local yarGen installation to v0.16b in cases in which you rely on the rule generation process. Follow me and Daniel Radu (Binarly) on twitter to stay up-to-date.
Improved Rule Generation
But let’s talk about the improved rule generation process.
As described in my previous articles, I try to divide the list of strings generated by yarGen into two different groups:
- Highly Specific Strings
These strings include C2 server addresses, mutextes, PDB file names, tool/malware names (nbtscan.exe, iexp1orer.exe), tool outputs (e.g. keylog text output format), typos in common strings (e.g. “Micosoft Corporation”) - Suspicious Strings
These strings look suspicious and uncommon but may appear in some exotic goodware, dictionary libraries or unknown software (e.g. ‘/logos.gif’, ‘&PassWord=’, ‘User-Agent: Mozilla’ > I’ve seen pigs fly – legitimate software contains the rarest strings)
In previous examples I always tended to combine these strings with magic header and file size. yarGen 0.15 and older versions generated those rules by default. The problem with these rules is that they do not detect the malware or tools to process memory.
Therefore I changed my rule generation process and adjusted yarGen to follow that example. As I said before, yarGen is not designed to generate perfect rules. Its main purpose is to generate raw rules that require the least effort to complete and could also work without further modification.
The following image shows how new rules are composed. They contain two main conditions, one for the file detection and one for the in-memory detection. I tried to copy the manual rule generation process as far as possible.
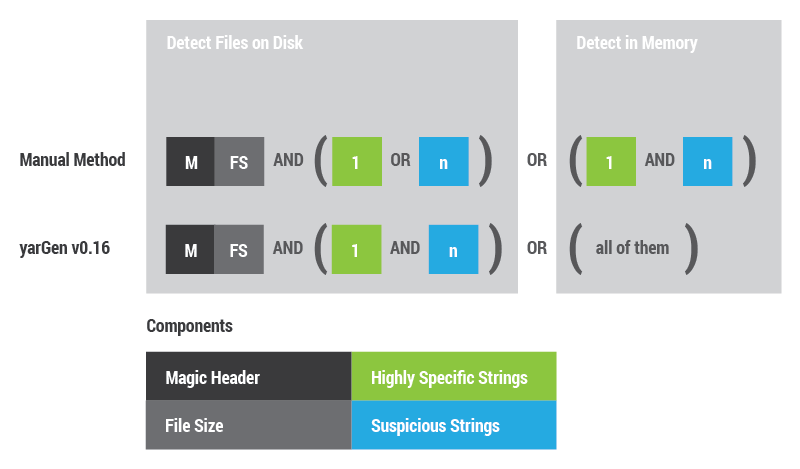
YARA rule composition (manual composition and yarGen v0.16)
The statement to detect files on disk combines the magic header, file size and only one of the highly specific strings OR a set of the suspicious strings.
For the in-memory detection I omit the magic header and file size. Highly specific strings and suspicious strings are combined with a logical AND.
The different statements (manual rule creation) look like this:
/* Detects File on Disk */ ( uint16(0) == 0x5a4d and filesize < 100KB and ( 1 of ($x*) or 4 of ($s*) ) ) or /* Detects Malware/Tool in Memory */ ( 1 of ($x*) and 4 of ($s*) )
Here is an example of a rule produced by yarGen v0.16 (sample Unit 78020 - WininetMM.exe). I shows a 'raw' rule without further editing and the 'scores' included as comments:
rule WininetMM {
meta:
description = "Auto-generated rule - file WininetMM.exe"
author = "YarGen Rule Generator"
reference = "not set"
date = "2016-04-15"
hash1 = "bfec01b50d32f31b33dccef83e93c43532a884ec148f4229d40cbd9fdc88b1ab"
strings:
$x1 = ".?AVCWinnetSocket@@" fullword ascii /* PEStudio Blacklist: strings */ /* score: '40.00' (binarly: 30.0) */
$x2 = "DATA_BEGIN:" fullword ascii /* PEStudio Blacklist: strings */ /* score: '36.89' (binarly: 27.89) */
$x3 = "dMozilla/4.0 (compatible; MSIE 6.0;Windows NT 5.0; .NET CLR 1.1.4322)" fullword wide /* PEStudio Blacklist: strings */ /* score: '32.53' (binarly: 5.53) */
$s4 = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0; .NET CLR 1.1.4322)" fullword wide /* PEStudio Blacklist: strings */ /* score: '20.00' (binarly: -7.0) */
$s5 = "Accept-Encoding:gzip,deflate/r/n" fullword wide /* PEStudio Blacklist: strings */ /* score: '10.35' (binarly: -1.65) */
$s6 = "/%d%s%d" fullword ascii /* score: '10.27' (binarly: 0.27) */
$s7 = "%USERPROFILE%\\Application Data\\Mozilla\\Firefox\\Profiles" fullword wide /* PEStudio Blacklist: strings */ /* score: '9.36' (binarly: -13.64) */
$s8 = "Content-Type:application/x-www-form-urlencoded/r/n" fullword wide /* PEStudio Blacklist: strings */ /* score: '5.61' (binarly: -9.39) */
$s9 = ".?AVCMyTlntTrans@@" fullword ascii /* score: '5.00' */
condition:
( uint16(0) == 0x5a4d and filesize < 300KB and ( 1 of ($x*) and all of ($s*) ) ) or ( all of them )
}
You may ask "Why do the 'DATA_BEGINS:' and '.?AVCWinnetSocket@@' do have such high scores"? Well, that's the reason why analysts needs the support of big data:
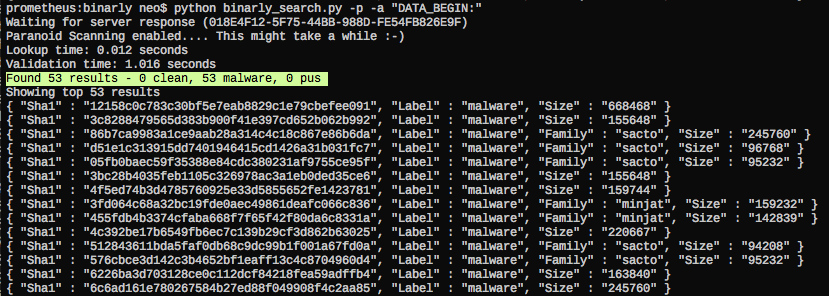
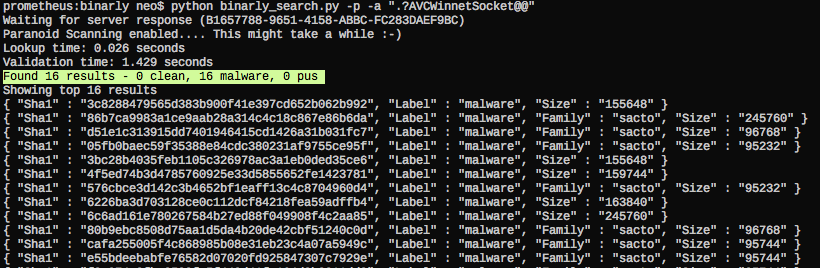
I have to add that Binarly offers two query modes (fast/exact) of which yarGen uses the 'fast' mode. An analyst that doubts the produced results would use 'exact' query mode to verify the results manually. Please ask Daniel about the details.
yarAnalyzer - Inventory Generation
The new version of yarAnalyzer allows to generate an inventory of your YARA rule sets. This features comes in very handy in cases in which you have to handle a big set of rules. The '--inventory' option generates a CSV file that can be prettied up in MS Excel or Openoffice Calc.
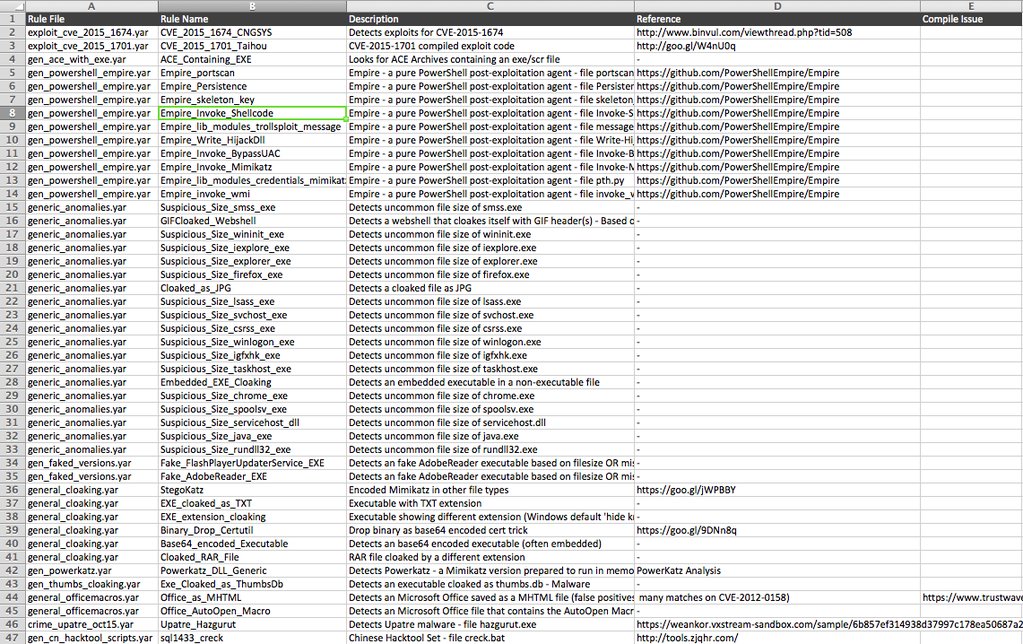
yarAnalyzer Inventory